Machines Learning to Solve Sign Problems

with Hyunwoo Oh, Yukari Yamauchi, Andrei Alexandru, Paulo Bedaque, Henry Lamm, Neill Warrington
September 5, 2022 at אוניברסיטת תל אביב

We must sample with respect to the quenched Boltzmann factor. Observables are computed via \[ \langle \mathcal O \rangle = \frac{\langle\mathcal O e^{-i S_I} \rangle_Q}{\langle e^{-i S_I}\rangle_Q} \]
The sign problem is measured by \[ \langle \sigma\rangle \equiv \frac Z {Z_Q} \sim e^{-\alpha^2} \]


The Boltzmann factor \(e^{-S}\) is complex. Sample with \(e^{-S_R}\) and reweight. \[ \langle\sigma\rangle = \frac{\int e^{-S}}{\int |e^{-S}|} \]

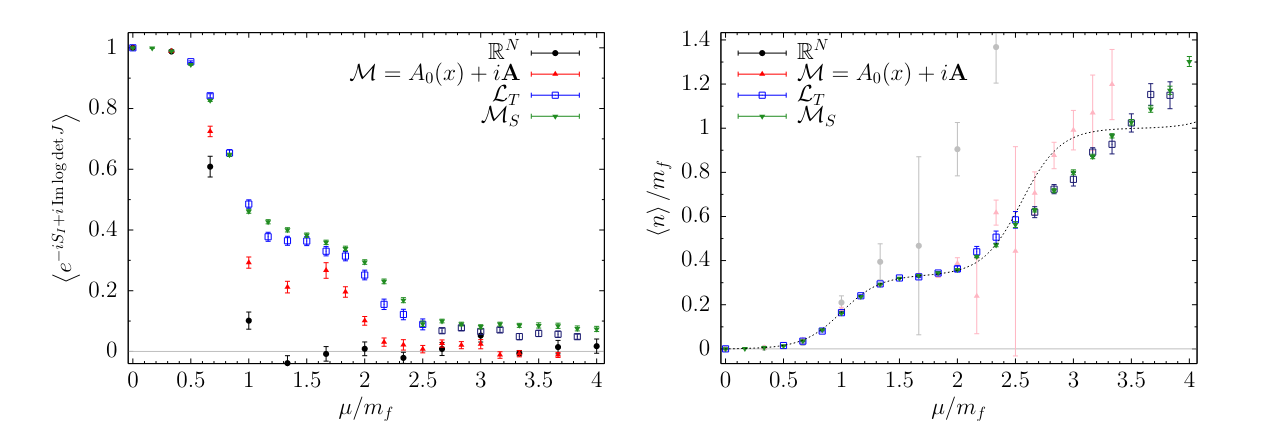
Relativistic fermions in \(1+1\) dimensions with a repulsive 2-body interaction. \[ S_{\mathrm{thirring}} = \frac 1 {2 g^2}\sum_{x,\mu} \big(1 - \cos A_\mu(x)\big)- \frac{N_f}{2} \log \det K[A] \]
The \(N_f=1\) theory is exactly solvable. Strong coupling marked by \(m_B \sim m_F\).
Evolve every point on the real plane according to the holomorphic gradient flow: \[ \frac{d z}{dt} = \left({\frac{\partial S}{\partial z}}\right)^* \] For short flow times, improves the average sign by decreasing the quenched partition function. (Maximally efficient!) \[ Z_Q = \int dz\, |e^{-S}| \]
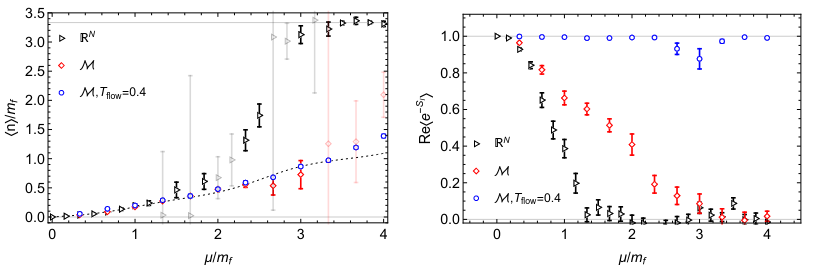
For an \(8^4\) QCD lattice, evaluating the Jacobian determinant requires a \(10^5 \times 10^5\) matrix. (\(\sim 10\) times larger than the Dirac matrix)
Algorithm:
Downsides:
Evaluating \(\langle \sigma \rangle\) itself is hard. The sign problem manifests as a signal-to-noise problem.
But, we don't need to! We just need to minimize \(Z_Q\), and \[\color{green} \frac{d}{d t}\lambda = - \frac{\partial}{\partial \lambda} \log Z_Q \] has the form of a quenched (i.e., sign-free) observable!
This isn't complex analysis---it's a general principle. Contour deformations:
Any strategy with those properties can be optimized in the same way.
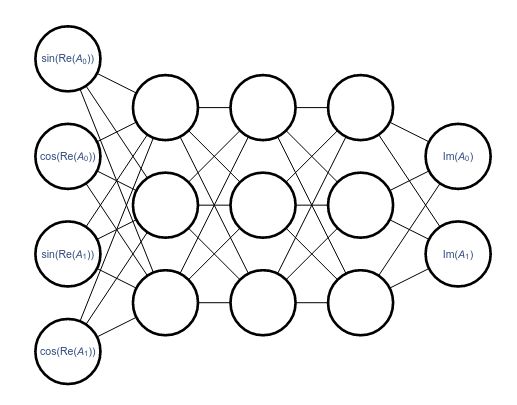
Best results obtained with a simple ansatz, rather than a deep neural network: \[ \mathop{\mathrm{Im}} A_0(x) = a + b \cos \mathop{\mathrm{Re}} A_0(x) + c \cos \mathop{\mathrm{Re}} 2 A_0(x) \]

Goal: sample from \(p(z)\)
A normalizing flow is a map \(\phi\) \[ \int_{-\infty}^x e^{-x^2} dx = \int_{-\infty}^{\phi(x)} p(z)\, dz \]
Sample from the Gaussian, then apply \(\phi\).
(Any easily sampled distribution can replace the Gaussian.)
What if \(\phi(x)\) is complex?
Complex normalizing flow \(\Rightarrow\) contour deformation
Here's a normalizing flow for scalar field theory:
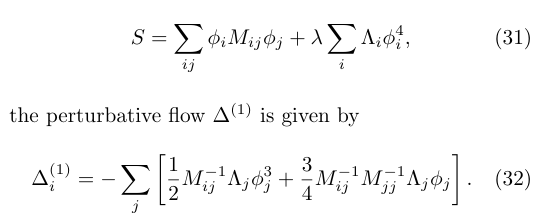
What if \(M,\Lambda\) are complex? Doesn't matter; still a good normalizing flow.
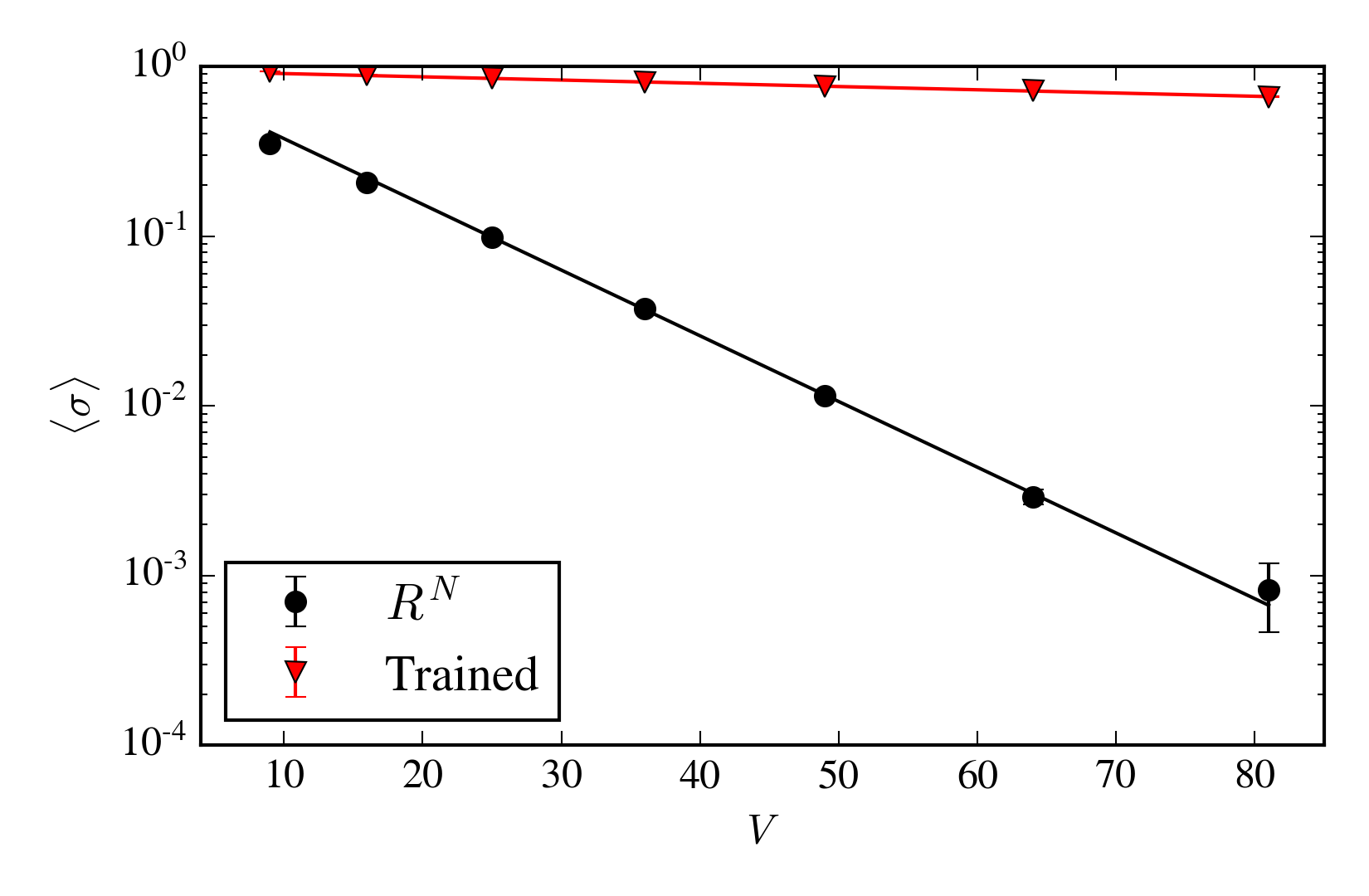
At \(\mathop{\mathrm{Im}}\lambda \ne 0\), this model has a sign problem. Train a contour as before, and the sign problem nearly disappears:
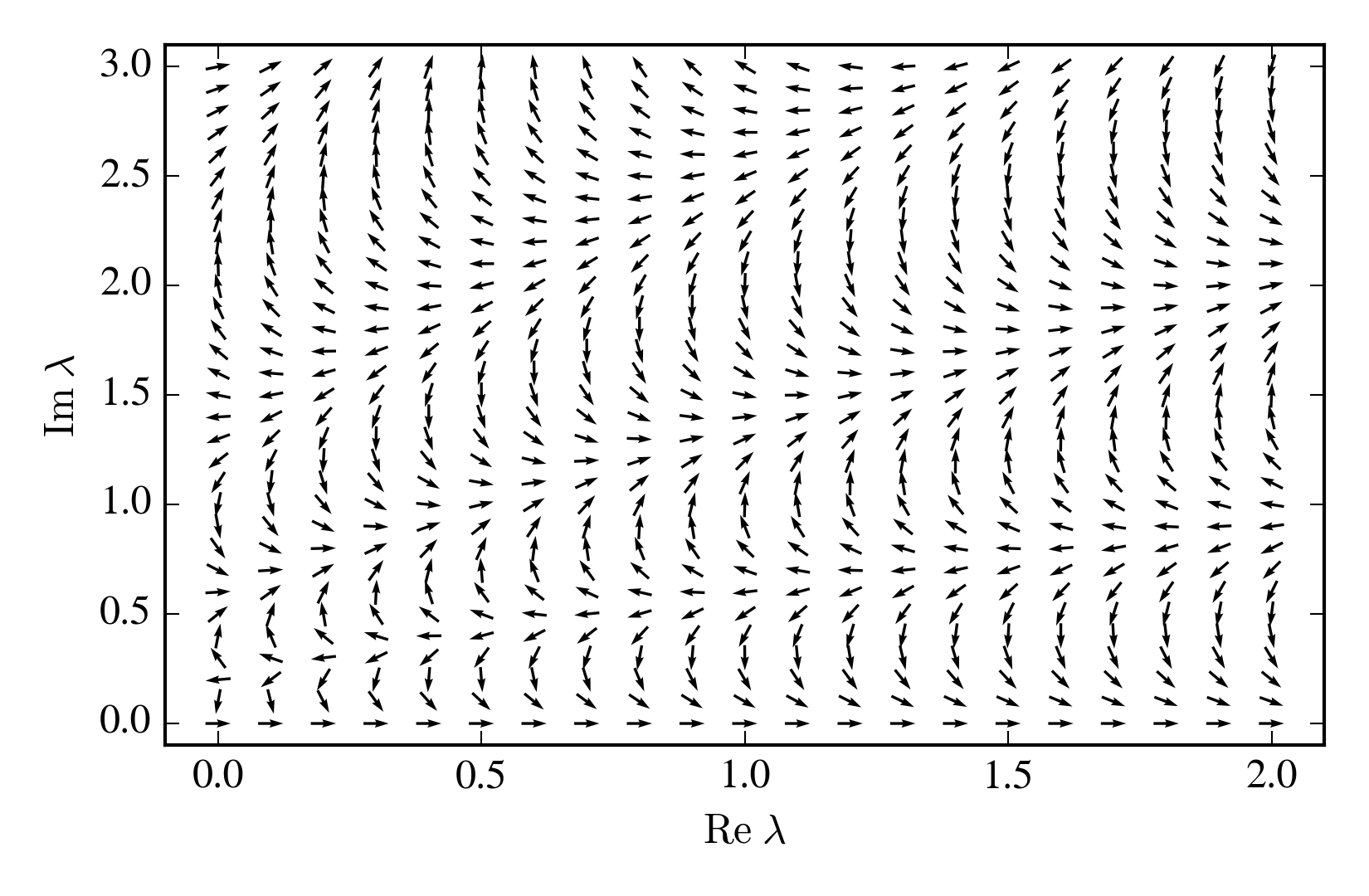
For \(\mathop{\mathrm{Re}}\lambda < 0\) the partition function can be defined only by analytic continuation. This is a "worse than infinitely bad sign problem".
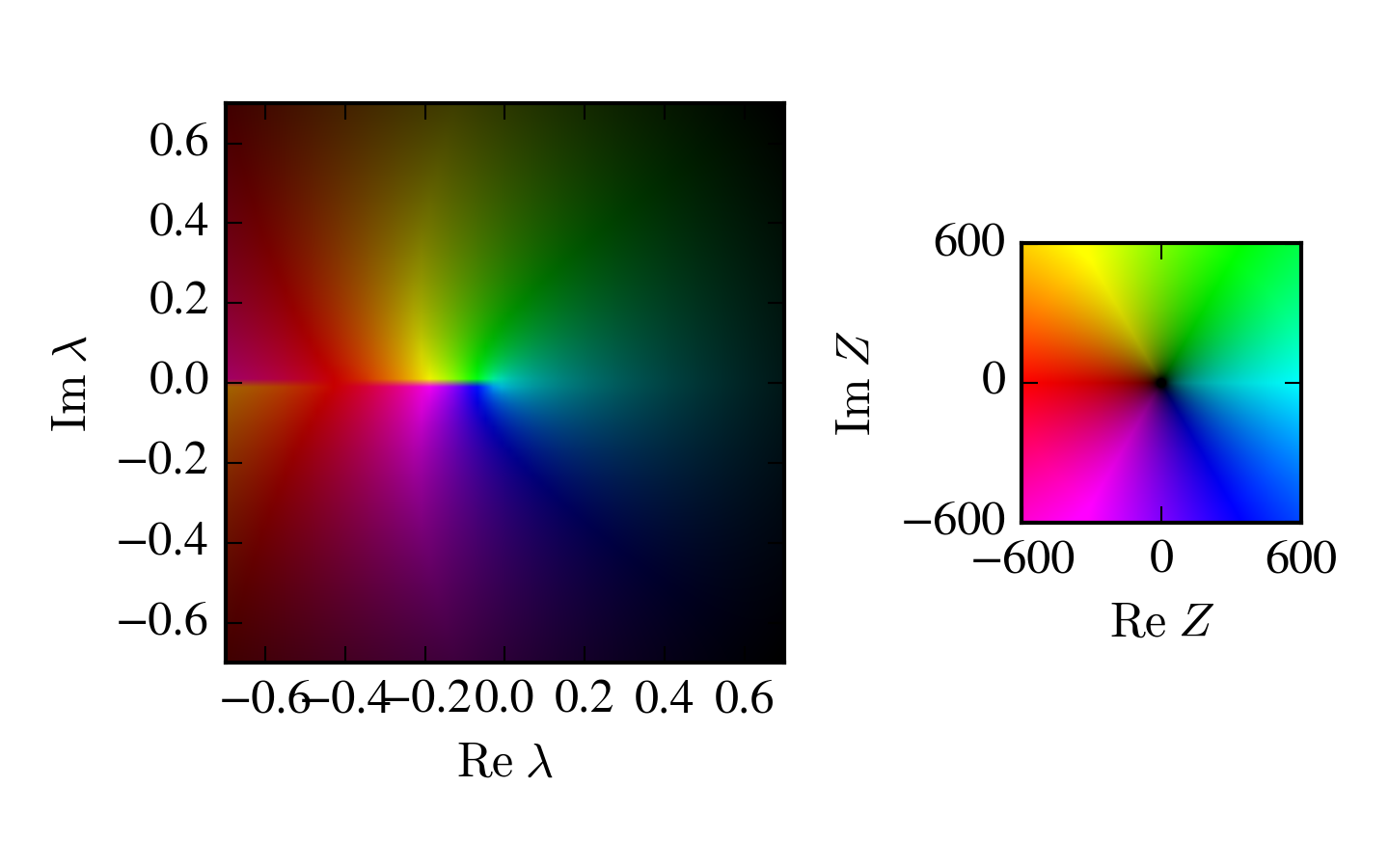
Wanted: a manifold such that \[ \left|\int e^{-S} \;d z\right|=\int \left|e^{-S} \;dz\right| \]
\[Z = 2 \pi \epsilon\]
Quenched partition function is \(O(1)\)
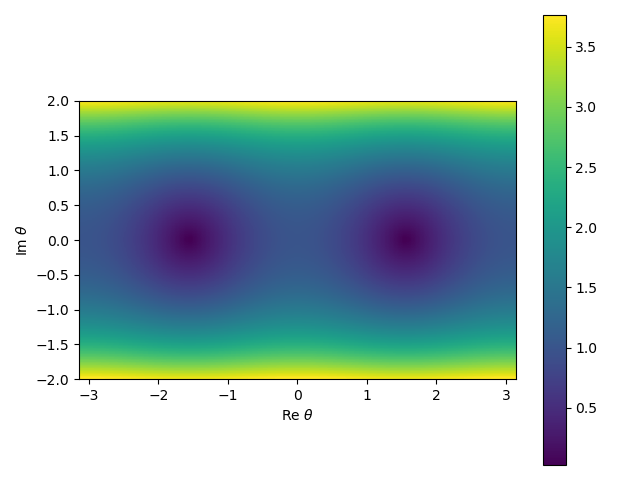
Physics (the partition function as a function of various sources) is unchanged, but the sign problem...
\[ Z_Q = \int \left|e^{-S(\phi)}\right| \ne \int \left|e^{-S(\phi)} - g(\phi)\right| = \tilde Z_Q \]All contour deformations are subtractions: \(\int d\phi\, f(\phi) - f(\tilde\phi(\phi)) = 0\)
This is not unique, but it is "close" to unique. Adding a generic function \(\tilde g \sim e^{-S}\) breaks the subtraction. Adding a generic function \(\tilde g \sim Z_Q\) is okay.
General trick to obtain functions that integrate to \(0\): \(g(\phi) = \frac{\partial}{\partial \phi_i} v_i\). (Almost useful for machine learning, but \(v \sim e^{-S}\) is required.)
Heavy-dense limit: a lattice expansion in large \(\mu\): \[ \det K[A] = {\color{blue}2^{-\beta V} e^{\beta V \mu + i \sum_x A_0(x)}} + O(e^{\beta (V-1) \mu}) \]
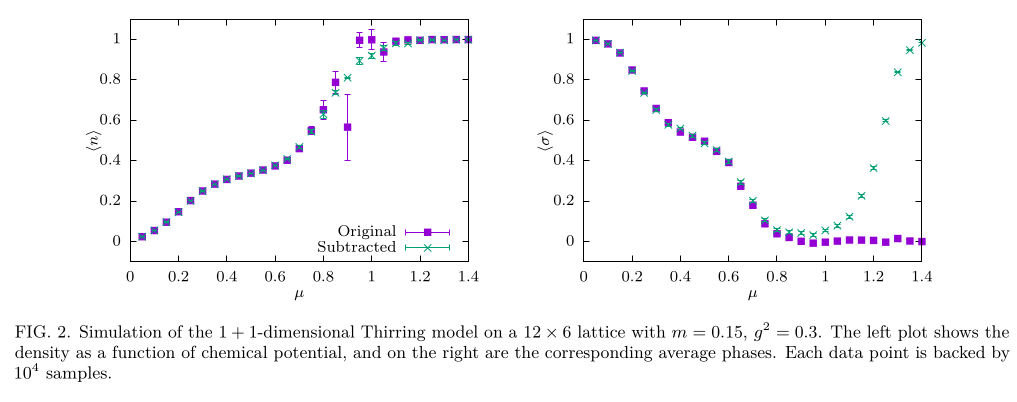
This form of subtraction is the same, at leading order in \(v\), as performing an infintesimal contour deformation.
Other procedures for measuring observables generally result in terrible signal-to-noise.
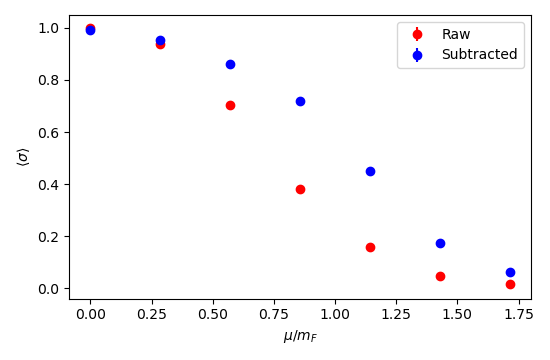
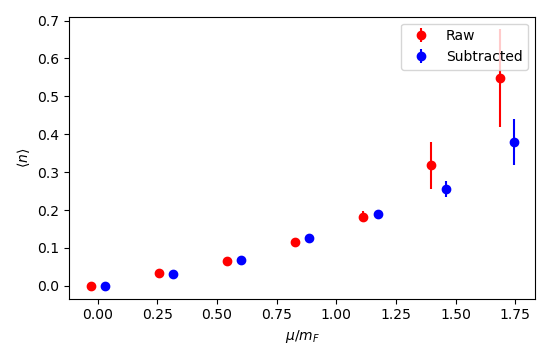
Training a 2-layer network on a 6-by-6 lattice with \(m_B = 0.33(1)\), \(m_F=0.35(2)\):